


Presence detection: Bee in a box
The ‘bee in a box’ algorithm enables you to detect presence in a given area of your smart home. It will enable your smart home system to know whether in a given area anybody is present or not. No special sensors or other additional hardware is required to do so. Bee in a box algorithm: The theory Imagine somebody handing you over a small box made out of cardboard. On the top side of the box, there is a yellow warning symbol ‘Warning: there might be a bee inside’. Continue reading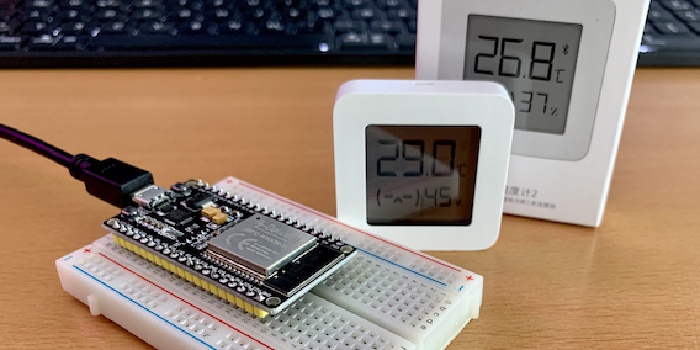
ESP32 as BLE Gateway for Xiaomi Mijia BLE Temperature & Humidity Sensor
Problem statement Too many unused BLE sensors, too much time during the COVID-19 lockdown - lets add more sensors! Just because we can… No seriously. I struggled a lot with too much humidity in the air in several areas of my house. After having a hot shower in the bathroom, the humidity condensed at the window, increasing the risk for mold growth. In the basement where our food supplies are stored, we had issues with salt getting wet. Continue reading
Monitor the pH of your reef tank with Tasmota
Monitoring water values of your fish tank is essential. To keep your reef-ecosystem alive, several dozens of water values need to be measured. This can be quite annoying to do that manually all the time. So I just started automating the measurement of them via Tasmota. One of the leading indicators for a fish tank is the pH level of the water. Measuring the pH level gives you a good indication for several other water values as well. Continue reading
Network segregation: IoT vs NoT
IoT devices became quite popular throughout the last years. Everything is connected, anytime. What sounds like a good idea, might actually result in a security hole in your network. As only the vendor knows what a device is actually doing, your IoT devices might bring some features with them that you don’t like. What is the problem with my IoT device? The short answer is: you own it, but you don’t control it. Continue reading
Unattended docker container updates
To keep your container infrastructure up to date and therefore secure, there are two primary objectives that you need to achieve: Keep the host‘s operating system up to date Keep the content of your containers up to date Update the operating system Updating your operating system is quite straight forward. Just use the well known package managers to do the job for you. E.g. for Debian this would be as easy as running apt-get update && apt-get upgrade on a regular basis. Continue reading
Using the cloud as panic room
Time to do something about it, and also about all other scenarios that threaten your digital heritage. Can the cloud be the safe place to backup all your data? But doesn’t uploading backups to the cloud also mean that others might be able to access it? In this article we will show a disaster recovery concept that you can use to backup infinite data amounts: It is free, easy to set up, and bullet prove.
Continue reading